 |
|
Non-technical Issues
- OGC Standards Dependencies - The OGC website presents the public standards as a list without relationships between, and as a result, it was difficult for us to determine where we should start reading because there are so many standards. It would be nice if on the home page for each standard, two standard sections were added: "Depends Upon" and "Is Depended Upon By" (I admit that better names could be chosen, but I hope the idea is clear). For example, if the SoS home page had a "Depends Upon" section listing O&M 1.0 and WCS, I would know that I should read those two standards along with SoS in order to implement an SoS service. A critical piece of information that greatly clarified the relationship between several closely related standards was the chart at the bottom of a SEEGRID page on OGC data interfaces by Simon Cox. Until reading that page, it just seemed that WFS, WMS, SoS, etc. were all just competing and slightly overlapping standards within the OGC. It turns out the right way to think about them is as independent layers of a service vision. In the end, what we'd like to see changed in the documentation and the OGC website is --
- classification of the standards -- For example, SoS, WMS, WFS would be classified as Service Standards, O&M and Web Service Common and Filter Encoding Simple Features as Foundational Conceptual Standards, and GML and SML as Markup Languages, for instance
- clarification of the relationship between the standards -- especially the dependency relationships, including the version numbers
Technical Issues
- What-Is-a-Feature Problem - In implementing the featured-related aspects of WMS, WFS, and SoS, we've run into the problem of determining what is a feature to expose. The OGC WFS specification literature appears deliberately vague on the definition of feature in order to allow the greatest generalizability to different domains, leaving the responsibility of specialization to particular applications. In the case of O&M, the specification does discuss a FeatureOfInterest and a SamplingFeature. We interpret the FeatureOfInterest as the object under observation and the SamplingFeature as associated to the act/conditions of observation, though the language in the specification seems to allow both to be the same. In the case of GroundWater/SurfaceWater-IE for USGS, the FeatureOfInterest is the aquifer or reach, and the SamplingFeature is the groundwater well or gaging station which makes observations on the FeatureOfInterest.
- Which Feature to Expose Problem -- Should we expose the FeatureOfInterest or SamplingFeature for the WFS and other services? In the 07-002r3 Observations and Measurements - Part 2 -Sampling Features document, it seems to us that the SamplingFeatures is added almost as an afterthought to the main Observations and Measurements UML model. The language in Section 6.2 Requirements for SamplingFeatures reinforces this impression. Indeed, in our (USGS) concrete use cases, we are most interested in exposing the observation stations and the parameter/analyte codes, and somewhat less interested in exposing the particular river reach. This is both because most users regard the FeatureOfInterest as implicit (and unvarying across the Observations of interest) and because existing expert users are accustomed to the fact that most existing USGS and non-USGS datasets follow the common practice of being organized by observation stations. I suspect this will change as the data becomes more accessible via OGC services, as new and casual users will likely want to explore the data by the FeatureOfInterest (for example, find all the observation stations along the Mississippi River) rather than by observation station. The root of this problem lies in the lack of connection between Figure 1 Summary of O&M Model
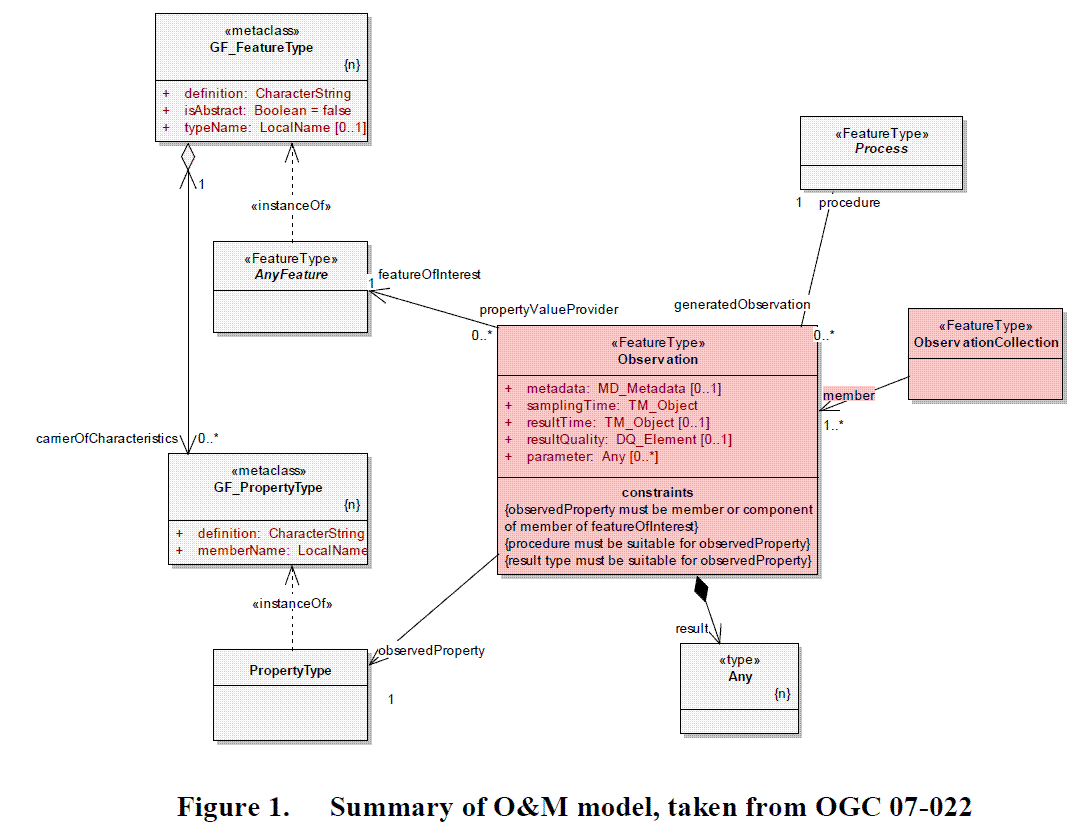
and Figure 3 Basic model for sampling features
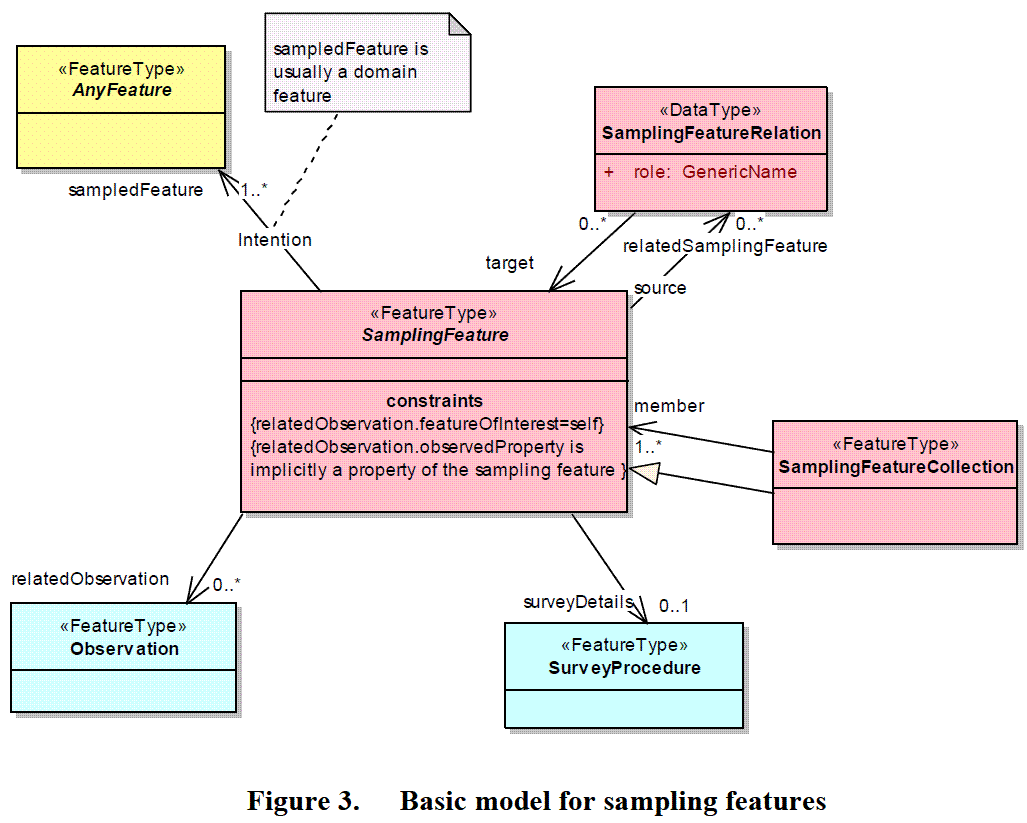
despite the fact that both figures appear within the same OGC specification document 07-002r3 Observations and Measurements - Part 2 -Sampling Features. A preliminary examination of these two figures raises two questions about how these two UML diagrams are supposed to be connected.
-
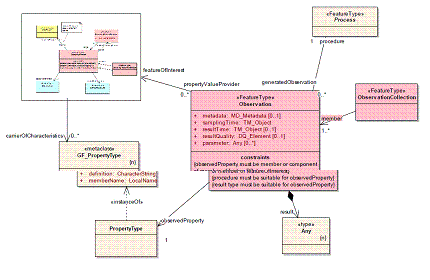
- Is a SamplingFeature simply a type of FeatureOfInterest, replaceable in the basic O&M model like so?
b. Or, is SamplingFeature an extension of the basic O&M model like so?
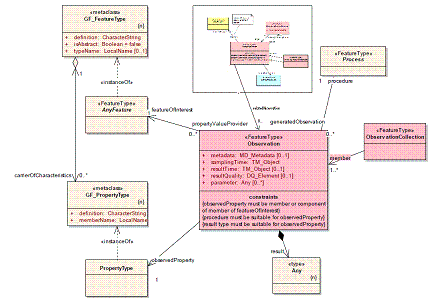
From our understanding, both interpretations are problematic. In the first case, SamplingFeature and FeatureOfInterest are exclusive, because an Observation can point to only a single associated Feature. The second case seems more workable, but the UML diagram doesn't seem right -- the SamplingFeature points to 0-to-many Observations. We think the direction of the arrow is wrong, as it requires the SamplingFeature to know about every associated Observation. In any case, a combined UML diagram would greatly clarify the situation.
To us, it appears the issue lies in the UML diagrams themselves and in their realization in XML. In the O&M specification, it says "A model for Observations and Measurements (O&M), based on patterns described by Fowler [1999][sic] is formalized in O&M Part 1." The cited source for the design is Chapter 3 of Martin Fowler's 1997 book Analysis Patterns. The chapter itself is titled "Observations and Measurements" and it is a guide to seeing how a basic design evolves as more aspects of the original problem is revealed. As the book predates the first draft of UML, the diagrams in the book are illustrated using the more traditional ER diagram notation. Through slow step-by-step changes of the original abstract model, Fowler shows how the evolution of a design is more than adding new attributes and boxes and arrows to an existing diagram. However, something seems to have been lost in the process of transitioning to the OGC O&M specification to suite OGC needs. While Fowler has several versions of O&M diagrams, the one below (Figure 3.10 from Analysis Patterns) is the one which most closely matches the intent of the OGC O&M standard.
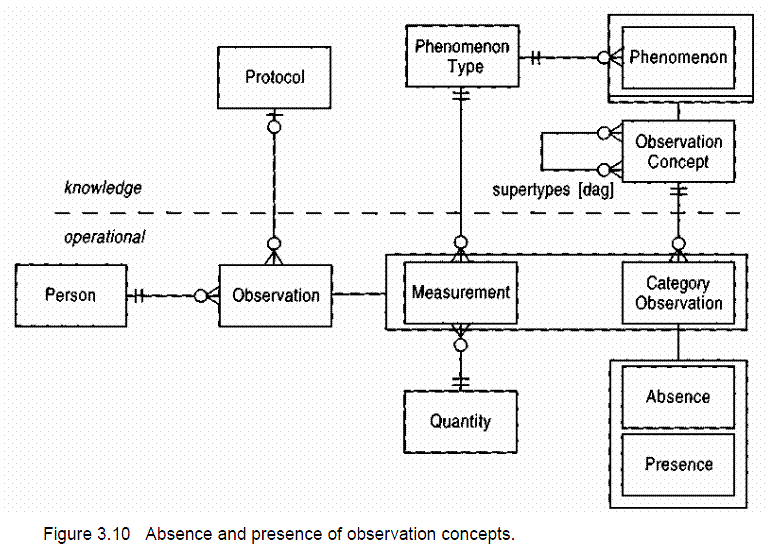
It's important to note that in this diagram, the Observation is the only thing connecting the Protocol, the Person/FeatureOfInterest, and the Measurement. That's a very key part of the design that's violated by the OGC O&M model, which we think leads to all sorts of problems, on which we'll elaborate later.
- (3, having trouble with wiki formatting) How to Expose Multiple Features Problem -- We would potentially want to expose both FeatureOfInterest and SamplingFeature to WFS as different feature types. While WFS is supposedly able to describe multiple FeatureTypes, the service interaction model doesn't seem rich enough to allow multiple feature types to be queried without considerable a priori knowledge on the part of the client. For example, the FilterCapabilities section of the WFS GetCapabilities seems to describe the capabilities for the entire service rather than for each FeatureType. At the very minimum, we'd like to be able to express that FeatureOfInterest uses a specified element/type from namespace A and SamplingFeature uses a specified element from namespace B, and that FeaturesOfInterest may be queried using one set of parameters while SamplingFeatures may be queried using another set of parameters. [Note: it is noted in section 8.2 that the properties of a feature are implicitly defined as the immediate children of the feature element in the xml schema sense, but this operationalization is problematic, as I'll explain later in problem #6]. It seems that from the WFS point of view, there isn't a distinction between SamplingFeature and FeatureOfInterest, and all the exposed FeatureTypes are merely facets of FeatureOfInterest. We would WFS to have knowledge of O&M, and to have mechanism to make a clearer distinction between FeatureTypes that belong to SamplingFeature and those that belong to FeatureOfInterest.
- (4) How to Expose Queryable Feature Properties Problem - In the water quality domain, an observation may be made regarding any one of many thousands of different substances. How do we expose this list of substances to the user? In WFS jargon, how do we expose this set of properties to the WFS client when there is no section of GetCapabilities or DescribeFeatureType for this purpose? As above, WFS handles this implicitly by the convention that the properties of the feature are its direct children, and avoids defining an extra service. We are of the opinion that this convention is untenable and would prefer a service to obtain a list of queryable FeatureProperties. See #6 below.
- (5) How to Expose Allowable Values of Enumerable Feature Properties - For example, suppose the SamplingFeature had an attribute type, with allowable values for USGS data of "gaging station" and "borehole". How does a client of the surface find out the set of allowable enumerated values for type? Again, if we subscribe to the convention that the properties are specified in the schema, then the set of enumerated values may be found by inspecting the type of the property and discovering that it is an enumerated type. However, in order to extend enumerated types, you have to have a new schema, so we think that enumerated types are not a general best practice. While it's certainly quite easy to extend or restrict enumerated types in schema, it's not easy to "discover" them (we think). Also, the use of enumerated types implies that unless domain implementers always come to consensus, any differences of opinion in enumerated types by an implementer requires a custom extension of the domain schema by that implementer. We think that a schema extension is a high cost task, one which should be avoided when the only difference between service implementer is the set of allowed enumerated values.
- (6) *Early Feature-Property Binding Problem -- In the specification, the properties of a feature are implicitly defined as the children of the feature element.
Web Feature Service 8.2 Request
3. The feature schema must be consistent with the OGC feature model. This means that the feature schema defines properties of the feature. The GML interpretation of this statement is that the elements nested immediately below the root element of a feature type define properties of that feature.
From p35 Analysis Patterns by Martin Fowler
Quantities can be used as attributes of objects to record information about them. This approach begins to break down, however, when there is a very large number of attributes that can bloat the type with attributes and operations. In these situations measurement (3.4)[sic] can be used to treat measurements as objects in their own right. This pattern is also useful when you need to keep information about individual measurements.
- attributes -- these are properties of the feature that are intrinsic and otherwise slow-changing. Examples would be ID, Name, Type, etc. These would be defined in the XML schema as the direct children of the Feature element.
- observed properties -- these are properties that conceptually are only attached to the feature through an observation. Generally, observed properties all implicitly require a time of observation. Examples are discharge rate, depth, temperature, etc. For the purposes of reporting, it is convenient to have these appear in the schema for the Feature, but it is important that the schema does not constrain the list of observed properties which do appear, for reasons given previously. Our suggestion is to have an
child whose content is xsd:any. - associated observation summary properties -- these are properties that summarize the set of observations attached to the feature. Conceptually, this kind of property is not attached to the feature object at all, but for outputting in xml, it's convenient to consider them to be "properties" of the feature. Again, for the purposes of output, it is convenient to have these appear in the XML as children of the Feature element, but it is critical that they not be constrained in any way by the schema. Similar to the case of ObserveredProperties, we recommend a child
element whose type is xsd:any
<Feature>
<ID>mendota</ID>
<Name>Lake Mendota</Name>
...
<ObservedProperties>
<Temperature time="09-09-2009" unit="F" observation-id="gcef.44553">72</Temperature>
...
</ObservedProperties>
<ObservationSummary>
<TotalObservations>112</TotalObservations>
<ObservedPropertyList>temperature,atrzine,mercury,iron</ObservedPropertyList>
</ObservationSummary>
</Feature>
- (7) Too Many Features Problem -- A lot of the standards don't seem to be designed to handle data at the scale needed for USGS data. For Us, if either of stations (SamplingFeature), parameter codes (FeatureProperties), or river reaches (FeatureOfInterest) is exposed in entirety, then the resulting GetCapabilities response xml document is far too long (subjective judgment here) to be handled by the kinds of clients in the interoperability experiment. The long response overwhelms the service client as well as produces a high load on the service provider, and it seems it is the responsibility of the standard to specify a protocol to keep this from happening. For example, the WMS GetCapabilities service returns the entire list of items in the Content section of the GetCapabilities response document by default. For USGS, this is potentially a list of over 1,300,000 items if nothing is excluded (for the interoperability experiment, the list is filtered to be manageable). While the Web Services Common specification allows the Content section to be omitted at client's discretion, it is returned in its entirety by default. Even if the client chooses not to download the Content initially, there is no OGC service mechanism to allow the client to later obtain the contents section in manageable pieces. There is an inadequate feature of a maxFeatures parameter which can be used to throttle the response, but this mechanism does not allow the client to somehow later retrieve the rest of the complete response without having to download the entire Content in a single chunk. Thus, a client who is interested in the entire Content section has only two very poor choices -- receive no Content at all, or allow itself to be overwhelmed by a million items. At this point, some would suggest implementing some kind of paging mechanism to allow piecemeal retrieval, but let us just say that in our opinion, __a paging solution is a cure which is worse than the original disease--. The OGC concept of SensorConstellation seems potentially useful, but it has no substantive OGC service support. There is no OGC service to query and return a SensorConstellation and then to drill down into the collection. Also, a division into SensorConstellations may not be enough unless SensorConstellations themselves are further subdividable -- after all, even with 100 SensorConstellations, USGS data would require an average of 13,000 items per SensorConstellation. Another concept mentioned in the specifications -- FeatureCollections -- is also not useful for this problem. FeatureCollections is not an organizational structure, it is merely a bag meant to collect features of disparate types to return to the user, and lack any kind of querying capability. In our opinion, what is lacking is a mechanism of nested features, supported by enhanced querying methods for drilling down into nested features.
- (8) Multiple Feature Dimension Problem -- While the WFS is supposedly capable of returning different FeatureTypes, none of the FeatureTypes are allowed to have any relationship to each other. For instance, we would like to be able to ask a service for all the observation stations along the Mississippi River, e.g. all the SamplingFeatures associated to a particular Feature of Interest. WFS does not allow us to query for features based on associations to a different feature, as the allowed query parameters must be "properties" of the target feature itself, not of an associated feature. The relationship between FeatureOfInterest and SamplingFeature is not part of the WFS spec, but even when O&M is brought into the picture, it does not enrich the WFS with the relationships underlying its model of observations and measurements. It would be too much to ask of WFS to be able to handle dependencies between arbitrary FeatureTypes, but it seems reasonable to us to ask SoS or O&M to extend WFS to be able to query along the known associations between the FeatureOfInterest and SamplingFeature through Observation. Furthermore, the FilterEncoding specification needs to be extended outside the capabilities of XPath. XPath is capable only of expressing same-document relationships, but the relationship between a SamplingFeature and a FeatureOfInterest is not naturally a same-document relationship as neither is contained in the other in the XML sense. We suspect that some kind of xlink/xpointer awareness will need to be built into the FilterEncoding. While there is usage of xlink within the WFS specification for the purposes of content retrieval via the the xlinktraversaldepth parameter, there is no usage of the standard for the purposes of querying.
- (9) Single or Multiple Result per Observation Problem -- The basic O&M model allows multiple results per observation, but all the results must be of the same property. In the water quality discipline, an "observation" might be the retrieval of a water sample which is then analyzed for a number of trace chemicals. The latter field observation cannot fit within the OGC Observation unless it is broken up into multiple Observations, one for each trace chemical, and then later recombined as the children of an ObservationCollection. This is a contortion we would like to avoid, if possible, for two reasons. a. The SoS doesn't indicate how an ObservationCollection should be treated differently from a simple single value Observation. b. With the current model, the common Observation metadata must be copied to each of the child Observations, and the identity semantics of the copied metadata is weaker than we would like it to be. This is an especially thorny problem and there's no obvious easy fix. Perhaps the answer is somewhere in Fowler's "Associated Observations" pattern, but we're still mulling over all the consequences. Perhaps in the end, this is an issue we'll have to abandon because all the solutions we can imagine are too complicated.
- (10) Associated Observation Problem -- This is another aspect of the multiple result per observation problem above. In section 3.11 of Analysis Patterns, Fowler is addressing this kind of problem when he talks about inferring a diagnosis of diabetes from indicators. Here is an example from USGS. For surface water, a gaging station will often measure the height of the water (stage) or the velocity of the water as a proxy for the discharge rate. The actual "observed" discharge rate is computed from the proxy measurements of stage or velocity via something called a "ratings curve". Hence to the single observation of the proxy property, there is an associated computed observation of discharge. As the computation of discharge from stage or velocity is not straightforward, real-time data feeds will contain only the proxy measurement, while warehoused data will contain both discharge and the proxy. The current O&M model is unable to express this kind of relationship.
- (11) Multiple Process Metadata per Observation -- A water sample observation will often consist of two parts -- collecting the water sample itself and then analyzing the sample in the lab. There are two pieces of process metadata that need to be associated to this single observation -- the method used to collect the sample, and the lab analysis method used to analyze the sample. Thee basic O&M model doesn't seem to allow for this because the connection between Observation and Process is 0..* to 1.
- (12) Multiple units of measure for aggregated services -- In the Groundwater Interoperability Experiment, GRCAN and USGS measure elevation in different units, meters and feet, respectively. The current FilterEncoding specification doesn't mention anything about units of measure except in the case of distance, so the unit of measure cannot be specified in the query. There are a couple of ways to deal with this:
- Allow FilterEncoding to specify units -- This also has the consequence that unless units are mandatory in the FilterEncoding, then somewhere in the service description there needs to be a place to define the preferred/default units, and the acceptable units. The specified unit of measure should then be used as the preferred unit of measure in the output, with conversion done by the service if necessary.
- Use the schema to specify a single choice of unit -- This seems too restrictive to us.
- Have the aggregated component services agree on a common unit -- This is workable, but not very agile. Consensus in general is hard to reach, and if there are many different properties in use, then agreement must be reached on each. It also doesn't solve the problem of how a client is to adapt itself when using two different but similar services which have not agreed upon a common system of units.
- Have the aggregator perform conversion to a common unit of measure -- In this case, the aggregator needs to custom configure itself to deal with conversions from each of its component services. This is doable, but not ideal.
Features Wish List (Out-of-Scope, probably)
- Expand the FilterEncoding specification to allow internal access of SoS GetObservations service to the results of WFS GetFeatures() query -- Currently, one can query WFS, retrieve a list of features, and then ask SoS for observations on those features. This requires the client to make two calls and keep the results of the first while making the second call. It would be nice if there were a new filter type of ServiceCallFilter which could bypass the client, to allow a single call where a ServiceCallFilter passed to SoS GetObservations is actually a set of of OGC call parameters to a different OGC service (GetFeatures, for instance), and the SoS service would be responsible for making the actual WFS call and parsing the results (if necessary) without having it pass through the original caller/client.
- Want some kind of a GetObservationsSummaryBySamplingFeature service -- In other words, we'd like to pass in an observation station and receive a summary of "properties" such as period of record, analytes tested, frequency of testing, etc. This would be useful in harvesting metadata for a more intelligent proxy. For example, GRCAN's GIS/GWML service receives a WFS call and then examines the filter parameters to ty to weed out the underlying services that would not return any results for the given filter parameters. Better decisions of this sort can be made if summary metadata for each of the component services or even at the station level can be harvested ahead of time and analyzed without drawing the entire set of results at each station.
Wow. that's a very long analysis. I read it with a lot of interest and I do have a couple of comments. (as I have the same problem with bullet formatting, I won't use any)
Non Technical Issue 1:
standard dependencies are listed in the foreword (Related Standards and Specifications) , but I agree that OGC standard is a jungle.Technical Issue 1/2:
You are reflecting on things that are actively debated (see SamplingFeature on this wiki and https://wiki.csiro.au/confluence/display/WaterML20/FeatureOfInterest on the CSIRO wiki). The SamplingFeature by virtue of being a Feature itself can be a featureOfinterest. One outstanding case when the featureOfInterest is the SamplingFeature is when the real feature of interest is not known.. yet (it's actually the goal of the observation). I totally agree with you that in our domain, the featureOfInterest should alway be a SamplingFeature because this is how people work. The pattern in this case is to use the Observation/featureOfInterest/SamplingFeature/sampledFeature/RealFeature pattern to link all those elements together. There are issues, but also proposed solution (patterns) in the wiki pages I listed above. It's mostly a matter of agreeing on them. Concerning the relation between Sampling and Observations UML, I don't think those two UML options you proposed are options, a real situation includes both associations. SamplingFeature/relatedObservation/Observation should be a consequence of Observation/featureOfInterest/SamplingFeature (although the model does not enforce it explicitly), Again, it should be a matter of pattern. About Fowler, I don't think the FeatureOfInterest is part of that diagram. The person is the observer, not the featureOfInterest, which is not explicit in the O&M spec but maybe refered in the metadata or in the Process. (3): I'm not sure I understand you point. I read this as a discussion over hard typing versus soft typing. You point out that WFS only exposes the XSD schema as a mean to discover the nature of the sampling feature and since that sampling feature that be the support of many types of observations, there is a problem for the user to figure out what phenomenons (observable properties) are available. There is a discussion that spills down to the other point regarding how to expose the observable properties of an observation if a property must be created for every possible substances. The problem is emphasise because of the rule that the featureOfInterest must also be a bearer of that property (the Observation must target a property that exists in the featureOfInterest). First, the rule that says that the featureOfInterest must carry the observedProperty of interest is relaxed when the fOi is a SamplingFeature because it is automatically satisfied by the topology of SamplingFeature/relatedObservation. 07-002r3, 7.1 says A SamplingFeature is distinguished from typical domain feature types in that it has a set of [0..*] navigable associations with Observations, given the rolename relatedObservation. This complements the association role ―featureOfInterest‖ which is constrained to point back from the Observation to the Sampling-Feature. The usual requirement of an Observation feature-of-interest is that its type has a property matching the observed-property on the Observation. In the case of Sampling-features, the topology of the model and navigability of the relatedObservation role means that this requirement is satisfied automatically: a property of the sampling-feature is implied by the observedProperty of a related observation. This effectively provides an unlimited set of ―soft-typed properties on a Sampling Feature. Second, this rule is being criticised a lot and I'm not sure it will stick. Not only it's impossible to enforced because of it 'fuziness', it would imply exactly what you explain, that the community creating a domain cover all possible and impossible properties. If we stick with SamplingFeature as featureOfInterest we're fine and compliant by default. Therefore we don't need to ever expand the properties of a feature. Furthermore, I think we should not confuse schema level properties with "phenomenon". The substances list that keep growing can be modelled as a component of a property (which would be 'concentration' or something like this). I agree that adding more properties is impractical to maintain. SWE common provides a way to externalise the description of observedProperty. OGC 07-001r1 has a couple of examples.
<?xml version="1.0" encoding="UTF-8"?>
<om:Observation gml:id="obsTest2" xmlns:om="http://www.opengis.net/om/1.0" xmlns:sml="http://www.opengis.net/sensorML/1.0.1" xmlns:swe="http://www.opengis.net/swe/1.0.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:gml="http://www.opengis.net/gml" xsi:schemaLocation="http://www.opengis.net/om/1.0 ../om.xsd http://www.opengis.net/sensorML/1.0.1 http://schemas.opengis.net/sensorML/1.0.1/sensorML.xsd">
<gml:description>Observation test instance: fruit identification</gml:description>
<gml:name>Observation test 2</gml:name>
<om:samplingTime>
<gml:TimeInstant gml:id="ot2t">
<gml:timePosition>2005-01-11T17:22:25.00</gml:timePosition>
</gml:TimeInstant>
</om:samplingTime>
<om:procedure>
<sml:ProcessModel>
<sml:method xlink:href="http://www.flakey.org/register/party/abc99"/>
</sml:ProcessModel>
</om:procedure>
<om:observedProperty xlink:href="urn:ogc:def:phenomenon:OGC:Species"/>
<om:featureOfInterest xlink:href="http://wfs.flakey.org?request=getFeature&featureid=fruit37f "/>
<om:result xsi:type="swe:ScopedNameType" codeSpace="http://en.wikipedia.org/wiki/List_of_fruits">Banana</om:result>
</om:Observation>
The observedProperty (species) is soft typed. The featureOfInterest is supposed to carry this property, but again, if it is a SamplingFeature, it has by virtue that the it points back to the Observation itself, which has this property soft-typed.
The composite nature of some phenomenon, as you discussed, can be covered (I think) using complex properties (again, no schema change)
<?xml version="1.0" encoding="UTF-8"?>
<om:Observation gml:id="COTest3" xmlns:om="http://www.opengis.net/om/1.0" xmlns:swe="http://www.opengis.net/swe/1.0.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:gml="http://www.opengis.net/gml" xsi:schemaLocation="http://www.opengis.net/om/1.0 ../om.xsd">
<gml:description>Complex Observation test instance</gml:description>
<gml:name>Complex Observation test 3</gml:name>
<om:samplingTime>
<gml:TimeInstant gml:id="ot1t">
<gml:timePosition>2005-01-11T17:22:25.00</gml:timePosition>
</gml:TimeInstant>
</om:samplingTime>
<om:procedure xlink:href="http://www.flakey.org/register/process/weatherStation3"/>
<om:observedProperty xlink:href="urn:ogc:def:phenomenon:SEEGrid:weather1"/>
<om:featureOfInterest xlink:href="http://www.ga.gov.au/bin/gazd01?rec=293604" xlink:role="urn:cgi:featureType:SEEGRID:framework:locality"/>
<om:result>
<swe:Record RS="weatherRecordDefinition.xml">
<swe:field>
<swe:Item>35.1</swe:Item>
</swe:field>
<swe:field>
<swe:Item>6.5</swe:Item>
</swe:field>
<swe:field>
<swe:Item>085.0</swe:Item>
</swe:field>
<swe:field>
<swe:Item>950.</swe:Item>
</swe:field>
<swe:field>
<swe:Item>32.0</swe:Item>
</swe:field>
<swe:field>
<swe:Item>clear</swe:Item>
</swe:field>
</swe:Record>
</om:result>
</om:Observation>
The observed property points back to a compound observation ( <?xml version="1.0"?> <swe:CompositePhenomenon xmlns:swe="http://www.opengis.net/swe/1.0.1" xmlns:gml="http://www.opengis.net/gml" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xlink="http://www.w3.org/1999/xlink" xsi:schemaLocation="http://www.opengis.net/swe/1.0.1 http://schemas.opengis.net/sweCommon/1.0.1/swe.xsd" gml:id="weather1" dimension="6"> <gml:name codeSpace="urn:ietf:rfc:2141">urn:ogc:def:phenomenon:SEEGrid:weather1</gml:name> <swe:base xlink:href="urn:ogc:def:phenomenon:OGC:Weather"/> <swe:component xlink:href="urn:ogc:def:phenomenon:OGC:AirTemperature"/> <swe:component xlink:href="urn:ogc:def:phenomenon:OGC:WindSpeed"/> <swe:component xlink:href="urn:ogc:def:phenomenon:OGC:WindDirection"/> <swe:component xlink:href="http://sweet.jpl.nasa.gov/ontology/property.owl#AtmosphericPressure"/> <swe:component xlink:href="http://sweet.jpl.nasa.gov/ontology/property.owl#RelativeHumidity"/> <swe:component xlink:href="http://sweet.jpl.nasa.gov/ontology/property.owl#Visibility"/> </swe:CompositePhenomenon>Now you bring a good point about how the user is supposed to discover what phenomenon are availables. You are right, scanning the schema is not an option, and we already ruled that one out. The common answer we get for that (the point have been raised in GeoSciML) is that is supposed to be handled in a Registry, some sort of catalog the user can read from and fetch information about what those URN (urn:ogc:def:phenomenon:SEEGrid:weather1) are supposed to represent. To be honest, the whole registry and resolver (a tool that tells the client where to get that registry in the first place) is quite muddy. We are at the bleading edge ! Right now, we rely on gentlemen agreement to make the system work (we 'know' what is expected) but the real architectural answer to this seems to be some external catalog. I think there is also some literature on SPS (Sensor Planning System) I did not have time to read just yet, including some incredibly boring architecture reports. Further down you mention the UML/XML mapping issues. The UML that is used here is a special profile of UML just for this purposem, see https://www.seegrid.csiro.au/twiki/bin/view/AppSchemas/SchemaFormalization#GML_Profile_of_UML (7) I'm not sure I understand your "too many feature" issue. Are you refering to the SOS Capabilities issue of listing all featureOfInterest ?. If it's the case, I agree. But on the other hand, if there are 1.3 M features that are queriable individually, they must be reported to the user somehow. I think the BBOX approach we used in the IE is the way to go. WFS also provide a LIKE operator so we can filter on the name. But, as you pointed out, there are no way to ask "all the well that have such an such measure of this phenomenon". Apparently, it's a catalog or a SOS operation. Couple of comments about some issues you listed:
- paging: fixed in WFS 2.0
- extended XPath : fixed in WFS 2.0 Filter 2.0 (see below)
<ogc:PropertyIsEqualTo> <ogc:PropertyName>sa:relatedObservation/omObservation/gml:name</PropertyName> <ogc:Literal>a name</ogc:Literal> </ogc:PropertyIsEqualTo>But, on the other hand, it's not garantee the inner feature will be serialized (it's up to the server), although you can force a property to be serialized (in theory) using wfs:Property. Furthermore, you can also use (again in theory, because I don't know any implemetation that does it) make a join. from 04-094 WFS
The mandatory typeName attribute is used to indicate the name of one or more feature type instances or class instances to be queried. Its value is a list of namespace-qualified names (XML Schema type QName, e.g. myns:School) whose value must match one of the feature types advertised in the Capabilities document of the WFS. Specifying more than one typename indicates that a join operation is being performed. All the names in the typeName list must be valid types that belong to this query's feature content as defined by the GML Application Schema. Optionally, individual feature type names in the typeName list may be aliased using the format QName=Alias. The following is an example typeName value that indicates that a join operation is to be performed and includes aliases: typeName="ns1:InwaterA_1m=A, ns1:InwaterA_1m=B, ns2:CoastL_1M=C" This example encodes a join between three feature types aliased as A, B and C. The join between feature type A and B is a self-join.But here, the real problem is to find an implementation that does it. (9) Multiple result per observation. swe might cover this, see previous examples, (10) compound observedProperty in SWE might cover this (see previous example) (11) A process can be a process chain, granted, you/we are on your own here. The only convincing example I saw is in ADX3 where they used ObservationProcess for geochemistry where each step of sample preparation is described. There is some activity in GeoSciML regarding this too. (12) Agree Discussing so many topic by text is quite tedious, I think we should bring those point to the next phone meeting. There are very important issues that you point out (specially about discovering phenomenon) that will be of interest to a lot of people trying to implement complex architecture. -- EricBoisvert - 17 Mar 2010


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Fowler_ObsMeas.GIF | manage | 23 K | 15 Mar 2010 - 17:41 | IlinKuo | Fowler Observations and Measurements Figure 3.10 |
| |
ObsMeasSummary.GIF | manage | 50 K | 15 Mar 2010 - 15:18 | IlinKuo | Observations & Measurements Summary |
| |
SamplingAsFoI.GIF | manage | 16 K | 15 Mar 2010 - 15:16 | IlinKuo | Sampling Feature as FeatureOfInterest |
| |
SamplingExtendsObsMeas.GIF | manage | 19 K | 15 Mar 2010 - 17:40 | IlinKuo | Sampling extends Basic O&M Model |
| |
SamplingFeatureModel.GIF | manage | 46 K | 15 Mar 2010 - 15:52 | IlinKuo | Sampling Feature UML diagram |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Webs
-
 AIP8
AIP8
- ASTROdwg
- AgricultureSummit
- AustraliaNewZealandForum
- AviationDWG
- BigDataDwg
- BusinessValueCommittee
- CATdiscuss
- CDBswg
- CRSdefinitionResolver
- CRSdwg
- CanadaForum
- ChinaForum
- CitSciIE
- CitizenScienceDWG
- ClimateChallenge2009
- CoveragesDWG
- DiscreteGlobalGridSystemsDWG
- EMSpectrumDWG
- EMspectrumDWG
- ERGuidance
- EUforum
- EarthCube
- EnergyUtilitiesDwg
- GML
- GeoSciMLswg
- GeoScienceDWG
- GeocodingAdHoc
- Geospatial3DMS
- HealthDWG
- HydrologyDWG
- I15swg
- ILAFpublic
- ISGdwg
- Ideas4OGC
- JAG
- JSONsubGroup
- JapanAssistance
- LandAdminDWG
- MLSdwg
- Main
- MarineDWG
- MassMarket
- MetOceanDWG
- NREwg
- NetCDFu
- NordicForum
- OGC
- PointCloudDWG
- QualityOfService
- SWEProCitSci
- Sandbox
- SmartCitiesDWG
- System
- TemporalDWG
- UKIAP2013
- UrbanPlanningDWG
- Vocabulary
- WCTileServiceSWG
- WPS
- WaterML
If you enter content here you are agreeing to the OGC privacy policy.
Copyright &© by the contributing authors. All material on this collaboration platform is the property of the contributing authors.
Ideas, requests, problems regarding OGC Public Wiki? Send feedback